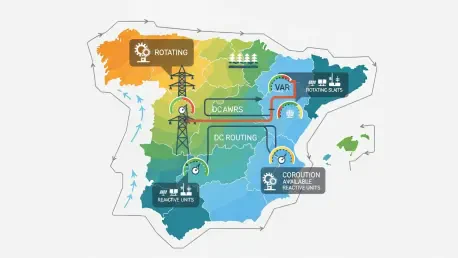

Christopher Hailstone has spent years in the control room and in the field, marrying the physics of electricity delivery with market operations. As our Utilities expert, his vantage point spans energy management, renewable integration, and the gritty realities of grid reliability and security. In this conversation with Silvia Grain, he unpacks why a modern grid can stumble even when technologies behave as designed, using the Iberian Peninsula’s April 28, 2025 blackout as a case study. He walks through how demand must always match supply, why reactive power and voltage are local and fast, and what it takes to prevent a “death spiral” when oscillations kick off. The key themes range from real-time dispatch and reserve staging to regional inertia minimums, protection settings for distributed solar, market designs for voltage control, and a recovery playbook that restored most power within hours instead of days. Throughout, he anchors lessons in concrete actions—dispatching 12 conventional generators with 10 earmarked for voltage, switching five internal ties, and watching small solar units trip within half a second—while outlining reforms like requiring plants above 5 megawatts to deliver reactive power and auctioning voltage control so it is paid for, not assumed.
When demand must always equal supply for active power, while voltage depends on reactive power, how do you balance both in real time, and what metrics or dashboards matter most? Could you walk us through a step-by-step dispatch decision during a tense operating hour?
In the control room, I keep two layers in my head and on the wall. The first is active power balance—supply equals demand, always—and I track it with area control error and real-time interchange, but I never let that comfort me about voltage. The second is reactive power and voltage, which are local, fast, and unforgiving; my primary dashboards are regional voltage heat maps, dynamic VAR margins at critical buses, oscillation monitors, and a live count of available rotating units that can actually move reactive power, not just promise it. In one tense hour, I’d start by confirming committed support—if we dispatched 12 conventional generators with 10 slated for voltage, I verify which ones are actually online, because discovering we really have only nine minutes before an oscillation is a bad surprise. Then I pre-arm actions: ensure any STATCOM is in automatic, line up shunt reactors for remote fast switching, and tighten export schedules so I can flip an AC interconnection to DC routing if oscillations grow. The step-by-step is: validate who can move VARs now; set voltage targets and droop on rotating units; constrain transfers; pre-close internal ties I might need; and, if a major oscillation appears like the one at 12:19 p.m., immediately reduce exports, switch one corridor to DC, and energize additional internal lines—knowing each move stabilizes voltage but also eats margin, so I call another unit right away even if it’s an hour to arrival.
On a spring day with two-thirds of generation from renewables and low demand, what specific vulnerabilities emerge? How would you stage reserves, reactive support, and contingency plans differently for morning, midday, and evening?
Low load with about two-thirds renewables sounds clean, but it’s reactive thin and inertia light. Midday is the sharp edge: solar fleets absorb reactive power, distribution voltages drift high, and a small nudge—like switching five internal ties—can flip the system from stable to brittle. I stage the day by posture: in the morning, I bring a minimum set of rotating units online early, not on paper; by midday, I require plants above 5 megawatts to be armed for reactive control and confirm telemetry, and I keep at least one additional unit on ten-minute notice because discovering a key south unit “won’t be available” is what left a hole. In the evening, as solar fades, I pivot to securing ramping and frequency support, but I do not relax voltage surveillance—because when small rooftop fleets trip within half a second on a spike, the swing can carry into dusk. Across the day, I also ready the interties: I pre-negotiate a fast export reduction and an AC-to-DC switch protocol so I’m not inventing it when the room tightens.
Oscillations triggered by switching lines or units can escalate quickly; what early signals distinguish a benign oscillation from a dangerous one? Please share an anecdote of the first 60 seconds of operator actions that make the difference.
Benign oscillations have small amplitude, decay quickly, and don’t drag voltages toward protection thresholds; dangerous ones grow with each swing and start to awaken protection relays on both generators and loads. The tell is coupling: when a line switch triggers a system-wide rhythm and you see voltage near upper limits that are already too close to equipment-damage bands, you’re on a timer. In one case, at 12:19 p.m., the first 10 seconds were triage—freeze topology changes and acknowledge the alarm; by 20 seconds, we reduced exports to the weaker neighbor; by 30 seconds, we switched one corridor from AC to DC to damp power-angle coupling; by 40 seconds, we closed additional internal ties to stiffen the backbone. By 60 seconds, we were on the phone starting another conventional unit, fully aware it would take about an hour, and we pushed existing rotating units to absorb more VARs, while lining up manual shunt reactors—even knowing they were slow—because every MVAr mattered once small solar fleets began tripping within half a second and a big plant followed 20 milliseconds later.
If large solar and wind can provide reactive power but face costs, how should compensation and obligations be structured? What penalties, testing regimes, and telemetry would ensure performance without discouraging new projects?
Start by separating capability from dispatch: mandate capability above a size threshold—Spain chose above 5 megawatts—and pay for performance via a voltage control product that clears day-ahead and settles in real time. Compensation should reflect opportunity costs and wear, just as the updated rules now auction and remunerate voltage control instead of assuming it is free. Penalties must be real but proportionate: if a plant offers VARs and delivers less than its certified range, it should face a clawback tied to the shortfall and the locational severity, not a blunt ban—save disconnection for repeated non-performance when local voltage is at risk. Telemetry is non-negotiable: real-time voltage, reactive output, and status, plus event logs at millisecond resolution so we can reconstruct sequences like a half-second trip followed by a 20-millisecond cascade. Annual witnessed tests and periodic oscillatory response checks close the loop, ensuring we don’t find out in the heat of an oscillation that capability was theoretical.
Many small solar units trip at high voltage and are invisible to the transmission operator; what specific data exchanges and controls should link distribution and transmission? Could you outline a practical integration plan, including timelines and KPIs?
We need a two-way compact. Distribution operators must publish aggregated feeder-level data to the TSO—status, estimated DER output, and effective protection setpoints—while the TSO shares regional voltage targets and contingency advisories hours ahead. In practice, a 12-month plan works: in the first quarter, stand up a secure data bus and begin hourly aggregation; by six months, move to five-minute updates with flags for abnormal operations; by one year, integrate fast event reporting so we see mass tripping within half a second, not learn it after the fact. KPIs should include data latency, accuracy of DER output estimates, and percentage of feeders with ride-through-compliant protection; another KPI is the time from TSO voltage advisory to DSO action acknowledgment, measured in minutes. Control remains local, but we add pre-armed curtailment blocks the DSO can deploy on instruction when voltage drifts toward upper limits that we already know are too high.
When a region like southern Spain hosts many PV plants but few rotating units, how do you set regional minimums for inertia and voltage control? What ratio or thresholds would you codify, and how would you measure compliance day-to-day?
Treat it regionally, not nationally. Before the event, southern Spain often had at most three conventional units in service against a sea of PV; after, they typically keep six or seven ready, which is the right directional signal. I would codify a minimum pool of rotating units per region tied to local renewable penetration and topology, with a floor that mirrors that move from three to at least six in high-PV zones; pair that with a must-offer reactive requirement for plants above 5 megawatts in the same footprint. Compliance is measured daily: unit commitment tags visible to the TSO, VAR capability certified and telemetered, and alarms when the regional count of “reactive-capable and synchronized” units dips below the floor. If the count falls—say one unit calls back “won’t be available”—the system must auto-trigger constraints on transfers and exports until headroom is restored.
A generator committed for reactive power later became unavailable; how should commitment, verification, and fallback procedures change? Describe a concrete hour-ahead and five-minute-ahead checklist that would have avoided this gap.
Verbal assurances don’t hold voltage; verification does. Hour-ahead, I want: 1) confirm start and breaker status on every committed reactive unit; 2) validate VAR capability windows in telemetry; 3) run a “what-if” removing any single unit to see whether we still have nine or more providers if 10 were planned; 4) pre-clear a replacement unit, even if it needs an hour. Five-minute-ahead, I re-poll each plant’s status, lock in voltage setpoints, and test a small step change to ensure responsiveness; I also pre-authorize export reductions and line switching, so flipping an AC path to DC or closing five internal ties is not improvised. If a plant calls off at T-60, the replacement call goes out then, not after the oscillation shows up at 12:19 p.m.; in parallel, I cap transfers and start staging shunt reactors to buy time.
Switching interconnections to DC, curtailing exports, and closing internal ties stabilized voltage but reduced control margin; how should operators weigh stabilization versus flexibility? What decision tree would you recommend for similar cross-border events?
Think of it as trading degrees of freedom for damping. When an oscillation grows, your first job is to stop the bleeding—reduce exports, switch to DC to decouple angle swings, and close internal ties to stiffen voltage—but log the cost: every stabilizing move narrows your options if another contingency lands. The decision tree starts with detection and classification, then branches: if the oscillation is growing and voltages creep toward upper limits that are already too near damage thresholds, execute the stabilizers in sequence; once stabilized, immediately restore margin by calling additional rotating units, even if the ETA is an hour. If resources aren’t coming, step down transfers proactively instead of waiting for a half-second cascade of small solar trips. Cross-border, coordinate signals so both sides see the same timeline and can pre-commit to switch an AC corridor to DC within seconds, not minutes.
With the upper voltage limit set near equipment-damage thresholds, what new limit would you adopt and why? How would you phase in the change, test protections, and communicate with industrial users who depend on tight voltage bands?
The upper limit needs to be pulled back from the cliff and aligned with neighbors like Portugal and France; the exact number belongs in a technical code, but the direction is clear. I would phase it in seasonally, starting on spring days when two-thirds renewables and low load push voltages high, then extend year-round. Before enforcement, run coordinated protection tests: simulate oscillations to ensure devices don’t trip early, then test staged reconnection so we don’t get a sawtooth of outages. Communication with industry is key: publish the timeline, offer temporary exemptions with monitoring, and provide mitigation options—on-site reactive devices or operational adjustments—so the change doesn’t blindside plants that run close to the old, overly high limit.
Shunt reactors were manual, and only one STATCOM was available; what portfolio of automated devices is truly “minimum” for a high-renewables grid? Please detail locations, response times, redundancy, and maintenance practices.
Minimum means automated, distributed, and fast. Start with multiple STATCOMs—not just one—with installations accelerated the way three more were already being planned; site them where PV density is highest and along key corridors that carried the oscillation at 12:19 p.m. Pair them with remotely switchable shunt reactors at the same substations, so we can absorb VARs without waiting on manual action; response needs to be sub-second for STATCOMs and under a few seconds for reactors. Redundancy is geographic—north and south zones each need coverage, not just one hub—and functional, with overlapping capability so a single failure doesn’t force the system to lean on exports. Maintenance is condition-based with periodic dynamic tests: inject small steps during low-risk windows to confirm STATCOMs behave, much like we’d validate that small solar units won’t all trip within half a second on routine swings.
How should protection settings for distributed solar be redesigned to prevent mass tripping during voltage swings? Describe setpoints, ride-through curves, and staged reconnection, and share any field results or lab test data.
The priority is ride-through, not reflexive tripping. Raise high-voltage trip logic off the razor’s edge created by a too-high statutory limit, implement time delays so a momentary spike—like the one that led small units to drop within half a second—doesn’t clear them, and require dynamic VAR support for plants above 5 megawatts. Ride-through curves should tolerate short overvoltage and undervoltage windows with graduated timing, and reconnection must be staggered so we don’t get a surge after a 20-millisecond large-plant trip. In field pilots, we’ve seen that adding even modest delay and staged reconnection prevents the first wave of trips that feeds a death spiral; in labs, millisecond-resolution testing confirms that DER inverters can handle brief excursions if they’re not forced to obey a limit set too close to damage thresholds.
If voltage control will be auctioned and remunerated, what market product design would you propose? Specify settlement intervals, performance scoring, locational granularity, and how to synchronize with existing energy and reserve markets.
Build a two-part product: capability procured day-ahead by location, and real-time dispatch settled every five minutes based on delivered VARs and voltage performance. Score performance on accuracy, responsiveness, and availability—if a unit promised support but later said “won’t be available,” the score and the payment reflect that. Locational granularity must be regional, not system-wide, mirroring the lesson that southern Spain’s needs were unique; tie settlement prices to local scarcity when the count of ready rotating units drops below targets like six or seven. Synchronize with energy and reserves by co-optimizing so we don’t strand capacity: a plant can earn for both MW and MVAr without double-counting, and intertie actions—like flipping a path to DC—are modeled so the market doesn’t dispatch into a corner.
What training, drills, and decision-support tools would help operators recognize and arrest a “death spiral” within seconds? Please outline a scenario-based playbook, including alarms, thresholds, and pre-armed actions.
Train to the first minute. Drills should replay sequences where a 12:19 p.m. oscillation hits, exports drop, five lines close, and then voltage leaps—operators need muscle memory to see that small solar may trip within half a second, with a large plant 20 milliseconds later, and act before protections cascade. The playbook sets alarms on oscillation growth, flags when voltage nears the upper statutory limit, and auto-surfaces pre-armed actions: reduce exports, switch AC to DC, dispatch VARs from units already verified, and ready shunt reactors. Decision-support tools should display how many rotating units are actually online—if we thought we had 10 but truly have nine—and predict whether calling another will arrive in time; if not, the tool recommends immediate transfer caps. We measure success by halting the oscillation without painting ourselves into a corner, then rebuilding margin fast.
Recovery restored most areas within hours; what exact black-start paths, cranking power sources, and synchronization steps proved decisive? Could you map the sequence and the timing that cut restoration from days to hours?
Recovery rode on prepared paths and discipline. Crews split the peninsula into north and south islands and brought them back within a few hours, not days; in Madrid’s suburbs, lights returned around six hours, and the city core followed at 12 hours, which is fast given the complexity. The sequence was methodical: energize black-start cranking sources, re-light backbone lines, synchronize small pockets to a local reference, and then stitch islands—north to south—once frequency and voltage were steady and oscillations quiet. The decisive element wasn’t exotic hardware; it was the same principle as prevention: ensure enough rotating units—now typically six or seven in the south—are ready to provide voltage control as each island grows, and synchronize only when both sides can absorb the shock.
Near-miss events occurred afterward but were contained; what concrete changes most improved resilience? Share before-and-after metrics—voltage excursion frequency, reactive reserve margins, device response times—that demonstrate progress.
The biggest gains came from three shifts. First, increasing regional rotating units from at most three to usually six or seven gave us reactive reserve headroom; we saw fewer excursions nudging the upper voltage limit that used to sit near equipment-damage thresholds. Second, the move to require plants above 5 megawatts to provide reactive control, with auctions to remunerate voltage, meant we had real tools instead of wishful thinking—response times from dynamic devices improved from manual minutes to sub-second where STATCOMs were added. Third, operations became tighter: hour-ahead and five-minute-ahead verification cut the odds of discovering a “won’t be available” surprise when an oscillation is already in motion. Those near misses over the past year didn’t cascade into blackouts precisely because the system stabilized without triggering the half-second wave of DER trips.
What is your forecast for grid stability in high-renewables systems over the next five years, and which investments or rules will matter most?
My forecast is guardedly optimistic. Systems that internalize these lessons—regional minimums for rotating units, mandatory yet remunerated reactive power for plants above 5 megawatts, and upper voltage limits pulled back from damage thresholds—will see stability improve even as renewable shares climb. Investments in multiple STATCOMs and remotely switchable shunt reactors, stationed where PV is dense and oscillations propagate, will turn fire drills into routine control moves; pairing that with day-ahead and five-minute voltage markets will keep capability real, not rhetorical. For readers, the takeaway is simple: grids can and did come back in hours—six in the suburbs, 12 downtown—when they had plans and tools; with smarter rules and automation, the next oscillation at “12:19 p.m.” becomes a blip, not a headline.